DeepSeek R2: Tin Đồn, Sự Thật Và Tương Lai Của AI Giá Rẻ
May 05, 2025
Xin chào anh em! Lại là tôi đây. Thế giới AI đang như cái chảo lửa, nóng hừng hực với những cái tên mới nổi. Hôm nay, chúng ta cùng “soi” một “ngôi sao đang lên” đến từ Trung Quốc: DeepSeek R2. Sau thành công của mấy “đàn anh” V2, V3, R1, liệu R2 có thực sự là “cú hích kiến tạo”, hay chỉ là “bom xịt”? Cùng tôi bóc tách nhé!
DeepSeek AI, dù mới ra mắt (thành lập tháng 07/2023), đã nhanh chóng gây chú ý với chiến lược mô hình “ngon, bổ, rẻ” và hay chơi bài “mở” (mã nguồn hoặc trọng số). Giờ đây, R2 – “truyền nhân” của R1, được kỳ vọng sẽ mang đến bước đột phá về suy luận đa ngôn ngữ, code, xử lý đa phương thức, và đặc biệt là cái giá “rụng rời con tim”.
Tuy nhiên, thông tin về R2 chủ yếu là… tin đồn lan truyền trên mạng xã hội, còn DeepSeek thì khá kín tiếng. Trớ trêu thay, những chi tiết “hot” nhất (Hybrid MoE 3.0, 1.2 nghìn tỷ tham số, giảm 97% chi phí) lại từ nguồn không chính thống tuồn ra. Đây là chiêu trò PR hay hàng “nóng” bị lộ thật? 🤔
Dù sao thì R2 cũng đang được xem là “Câu trả lời táo bạo của Trung Quốc trong cuộc đua AI”, nhất là khi có tin đồn nó được huấn luyện bằng chip “cây nhà lá vườn”. Cùng tôi “mổ xẻ” R2 xem thực hư thế nào!
2. “Bung Nắp Capo”: Giải Mã Kiến Trúc (Đồn Đại) Của R2
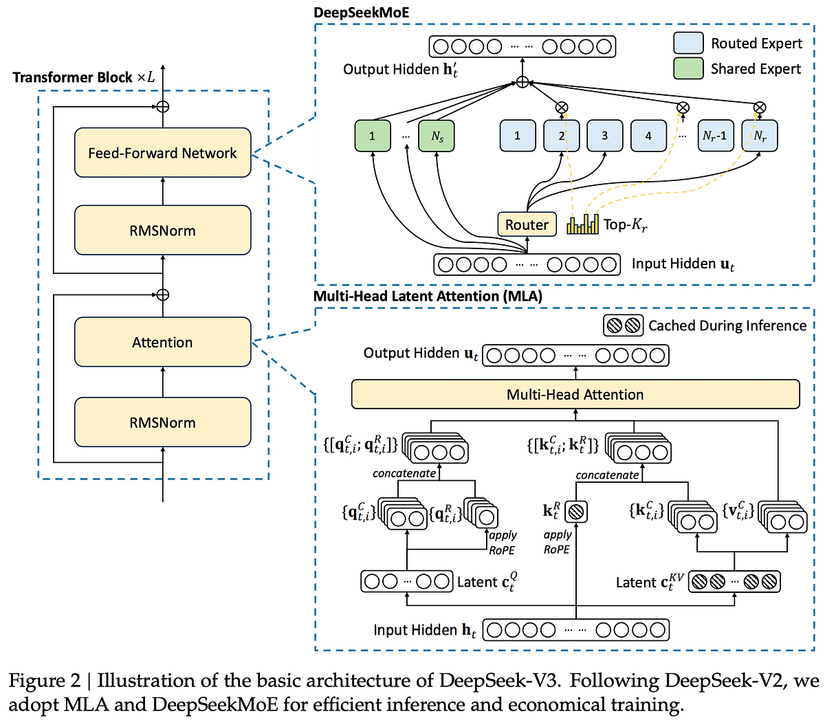
Để hiểu sức mạnh R2, phải nhìn vào “nội thất” của nó, khả năng cao là kế thừa và nâng cấp từ V2/V3:
Nền Tảng Từ V2/V3:
Multi-head Latent Attention (MLA): Cơ chế attention cải tiến giúp tăng tốc suy luận bằng cách nén KV cache (điểm nghẽn của Transformer truyền thống).
DeepSeekMoE: Kiến trúc Mixture-of-Experts (MoE) độc quyền, huấn luyện model siêu lớn mà tiết kiệm chi phí nhờ tính toán thưa (chỉ kích hoạt các “chuyên gia” phù hợp thay vì cả mạng lưới).
Cải Tiến Khác Từ V3: Cân bằng tải giữa các “chuyên gia” mà không cần hàm mất mát phụ trợ, dự đoán đa token… có thể được R2 kế thừa. Chiến lược cốt lõi của DeepSeek là hiệu quả, không chỉ chạy đua tham số. Đây là nước đi thông minh khi có thể bị hạn chế chip phương Tây.
“Hybrid MoE 3.0” – Bí Ẩn Rò Rỉ: “Hybrid” (Lai) ở đây nghĩa là gì? Có thể là cơ chế cổng phức tạp hơn, kết hợp lớp dày và thưa, hay phân đoạn chuyên gia cực mịn? Tất cả chỉ là đoán mò, chờ DeepSeek lên tiếng.
Bài Toán Tham Số: Tin đồn R2 có 1.2 nghìn tỷ (Trillion) tham số, nhưng chỉ kích hoạt 78 tỷ (Billion) (khoảng 6.5%) cho mỗi token. Tỷ lệ này tương tự V2/V3. Giống như thư viện khổng lồ, nhưng chỉ vài khu vực sáng đèn khi cần, tiết kiệm “điện” (chi phí tính toán).
“Đại Hồng Thủy” Dữ Liệu Huấn Luyện: R2 được cho là đã “nuốt” 5.2 Petabyte dữ liệu, gồm cả lĩnh vực chuyên sâu (tài chính, luật, bằng sáng chế). Cho thấy DeepSeek nhắm đến ứng dụng doanh nghiệp giá trị cao, không chỉ chatbot thông thường. Đây là lĩnh vực cần kiến thức sâu và xử lý văn bản dài – thế mạnh của DeepSeek. Nhưng xử lý dữ liệu khổng lồ cũng có rủi ro về chất lượng và nhiễm bẩn.
Năng Lực Cốt Lõi (Hứa Hẹn/Rò Rỉ):
Suy Luận Đa Ngôn Ngữ Vượt Trội: Xuất sắc về logic, giải quyết vấn đề nhất quán đa ngôn ngữ (đặc biệt Trung, Anh, Á), khắc phục điểm yếu của model phương Tây.
Nâng Cấp Khả Năng Lập Trình: Cải thiện tạo mã, hiểu kiến trúc, gỡ lỗi, cạnh tranh với model code chuyên biệt.
Chức Năng Đa Phương Thức Mạnh Mẽ: Xử lý/tạo văn bản, ảnh, âm thanh, video cơ bản. Điểm số COCO ấn tượng (92.4 mAP cho phân đoạn đối tượng) là minh chứng tiềm năng. Bước tiến lớn so với model cũ chủ yếu là văn bản.
“Phép Thuật” Huấn Luyện:
Generative Reward Modeling (GRM): Model tự tạo feedback, hiểu ngữ cảnh sâu hơn, phù hợp giá trị con người mà không cần nhiều dữ liệu thủ công. Liên quan đến học tăng cường (RL) của R1.
Self-Principled Critique Tuning (SPCT): Model tự đánh giá kết quả theo nguyên tắc, cải thiện suy luận, giảm “ảo giác”, tăng mạch lạc. Gợi nhớ cơ chế tự phản ánh (“Aha moments”) của R1.
Kết hợp GRM/SPCT có thể giúp model tự cải thiện, giảm phụ thuộc RLHF tốn kém, đẩy nhanh huấn luyện, tạo model phù hợp suy luận phức tạp.
3. Giá Cả “Rụng Rời”: R2 Có Thực Sự Rẻ Như Tin Đồn?
Điểm “nóng” nhất về R2 chính là giá!
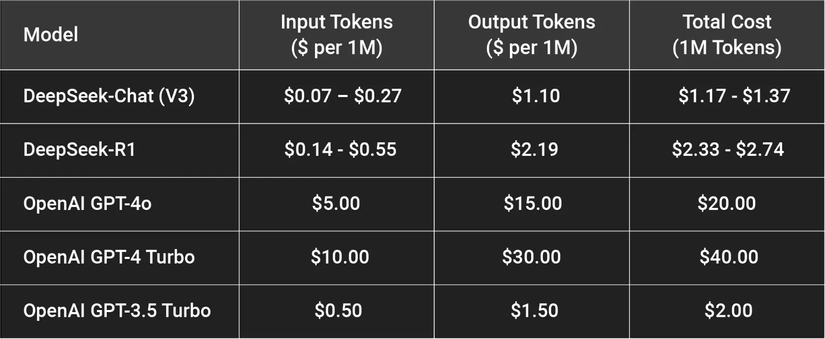
Con Số Gây Sốc: Giảm 97.3% chi phí/token so với GPT-4 Turbo/4o? Giá đồn đoán: $0.07/triệu token vào, $0.27/triệu token ra.
Đặt Vào Bối Cảnh:
GPT-4 Turbo từng có giá $10/$30. GPT-4o rẻ hơn nhưng giá R2 vẫn thấp không tưởng.
R1 đã rẻ (1/10 – 1/20 OpenAI). Giá R2 đồn đoán ngang R1 hiện tại.
V3 được cho rẻ hơn GPT-4o 30 lần. R2 nếu đúng còn rẻ hơn nữa!
Làm Sao Có Thể? (Giả Thuyết):
Hiệu Quả Kiến Trúc: Hybrid MoE 3.0 kích hoạt ít tham số (78B/1.2T).
Yếu Tố Phần Cứng: Dùng chip Huawei Ascend 910B. Đạt hiệu suất sử dụng chip 82%, 512 PetaFLOPS FP16 (tương đương 91% Nvidia A100 cùng quy mô, dù tốn điện hơn). Đây là tín hiệu địa chính trị/công nghệ quan trọng, nỗ lực tự chủ khỏi Nvidia/Mỹ giữa lệnh cấm vận.
Đổi Mới Huấn Luyện: GRM/SPCT giảm chi phí feedback từ người.
Tích Hợp Dọc/Hệ Sinh Thái: Đối tác (Tuowei, Sugon…) tối ưu chuỗi cung ứng.
Tiềm Năng Phá Vỡ Thị Trường:
Dân Chủ Hóa AI: Giúp SME, startup, dev độc lập tiếp cận AI mạnh.
Cuộc Chiến Về Giá: Buộc đối thủ lớn (OpenAI, Anthropic, Google) giảm giá mạnh.
Thay Đổi Trọng Tâm: Khuyến khích ngành tập trung vào hiệu quả kiến trúc.
Nếu đúng, giá rẻ có thể biến AI thành dịch vụ phổ thông, thúc đẩy áp dụng rộng rãi, kích hoạt nghịch lý Jevons (giá thấp -> nhu cầu tăng vọt). Cuộc chiến giá có thể siết lợi nhuận và củng cố thị trường quanh người chơi hiệu quả cả về năng lực lẫn chi phí.
Góc Hoài Nghi (Và Chút Hài Hước):
Giá này có bền vững không? Đã gồm R&D, hạ tầng hay chỉ chi phí vận hành? Có phải giá khuyến mãi?
Vẫn là “tin đồn”. Đối thủ chắc “xỉu ngang” khi nghe tin, nhưng cứ chờ xem DeepSeek có “chơi lớn” thật không! 😉
4. So Kè Hiệu Năng: R2 (Có Thể) Sẽ Đứng Ở Đâu?
Đánh giá hiệu năng R2 giờ như đoán thời tiết xa vời. Phải dựa vào mảnh ghép và suy đoán:
Dữ Liệu Rò Rỉ R2:
Tuân Thủ Chỉ Thị: 89.7% trên C-Eval 2.0 (benchmark tiếng Trung).
Thị Giác Máy Tính: 92.4 mAP trên COCO (phân đoạn đối tượng), cải thiện đáng kể so với CLIP.
Tuyên Bố Chung: Hiệu năng “tương đương GPT-4-Turbo” hoặc “trong tầm GPT-4o”.
Bài Học Từ R1 và V3:
DeepSeek R1: Gần bằng GPT-4o/o1-preview về suy luận/toán, mạnh về code (thắng về giá), viết lách xuất sắc. Xếp hạng cao trên Chatbot Arena.
DeepSeek V3: Ngang/hơn GPT-4o/Claude 3.5 Sonnet về suy luận/toán. Điểm MMLU cao, Elo Arena cao. Cạnh tranh tốt.
Bối Cảnh Chatbot Arena: Đánh giá dựa trên sở thích cộng đồng. R1/V3 dẫn đầu nhóm nguồn mở, cho thấy chúng không chỉ mạnh mà còn làm hài lòng người dùng (có thể nhờ GRM/SPCT/distillation).
Bảng So Sánh Tổng Hợp (Dự Kiến): (Lưu ý: Dữ liệu R2 là tin đồn, các model khác có thể thay đổi)
Tính Năng
DeepSeek R2 (Rò rỉ/Dự kiến)
DeepSeek R1
DeepSeek V3
GPT-4o / 4.5*
Claude 3.7 Sonnet*
Llama 4 Maverick*
Gemini 2.5 Pro*
Kiến trúc
Hybrid MoE 3.0 (?)
MoE, RL-focused
MoE, MLA, Aux-Loss-Free
MoE? Dense?
Dense? Hybrid Reasoning?
MoE
MoE?
Tham số (Tổng/Kích hoạt)
1.2T / 78B
671B / 37B (Base V3)
671B / 37B
? / ?
? / ?
? / 17B
? / ?
Cửa sổ ngữ cảnh
>=128K?
128K
128K
128K
200K
10M
1M
Benchmark Nổi Bật
C-Eval 2.0: 89.7%
MMLU: 90.8, Arena Elo: 1358
MMLU: 88.5, Arena Elo: 1373
MMLU: ~86-89, HE: 90.2
GPQA: 84.8, SWE: 70.3
MMLU: 85.5, MATH: 61.2
GPQA: 84.0, LiveCode: 70.4
Thị giác (COCO mAP)
92.4% (Object Seg.)
Không hỗ trợ trực tiếp
Không hỗ trợ trực tiếp
Hỗ trợ đa phương thức
Hỗ trợ đa phương thức
Hỗ trợ (ChartQA: 85.3)
Hỗ trợ đa phương thức
Chi phí ($/M tokens)
$0.07 / $0.27
~$0.14 / $0.28 (API R1-Lite)
~$0.14 / $0.28 (API V3)
$5 / $15 (GPT-4o)
$3 / $15
~$0.06 / $0.18 (Scout)
?
Trạng thái (Q2 2025)
Tin đồn/Chưa ra mắt
Đã phát hành (API/Open)
Đã phát hành (API/Open)
Đã phát hành (GPT-4o)
Đã phát hành
Đã phát hành
Đã phát hành
Ngoài Benchmark: Benchmark không phải tất cả. Tính dễ dùng, an toàn, thiên vị, tương thích cũng quan trọng. DeepSeek từng gặp vấn đề về tài liệu/giao diện.
Nhìn chung, DeepSeek có chiến lược 2 mũi nhọn: R (Reasoning – suy luận) và V (Versatile – tổng quát, rẻ). R2 có vẻ kết hợp cả hai. Lịch trình phát hành dày đặc cho thấy chu kỳ phát triển năng động.
5. Giải Phóng R2: Ứng Dụng “Trong Mơ”
Nếu R2 mạnh và rẻ như đồn, ứng dụng sẽ vô biên:
Siêu Cường Lập Trình: Trợ thủ đắc lực: tạo code phức tạp, tái cấu trúc, gỡ lỗi, giải thích, xây dựng cả ứng dụng.
Phá Vỡ Rào Cản Ngôn Ngữ: Truy xuất thông tin xuyên ngôn ngữ, dịch trực tiếp, hỗ trợ khách hàng toàn cầu, tạo nội dung đa thị trường.
Tầm Nhìn Cho Tương Lai: Hiểu/mô tả ảnh, trả lời câu hỏi về ảnh, phân tích video, tạo biểu đồ từ văn bản, phân đoạn đối tượng. Kết hợp đa phương thức trong 1 model rẻ giúp đơn giản hóa phát triển ứng dụng AI phức tạp.
Chuyên Môn Hóa Ngành (dựa trên dữ liệu huấn luyện đồn đoán):
Tài chính: Phân tích báo cáo, mô hình định lượng, kiểm tra tuân thủ.
Luật: Phân tích/tóm tắt tài liệu pháp lý, rà soát hợp đồng, nghiên cứu bằng sáng chế.
Khác: Y tế (chẩn đoán), bảo hiểm (thẩm định), marketing, giáo dục (gia sư ảo), nghiên cứu khoa học. Cửa sổ ngữ cảnh dài (dự kiến) + dữ liệu chuyên sâu = định vị mạnh cho tác vụ doanh nghiệp.
Ứng Dụng Rộng Rãi Khác: Kinh doanh thông minh (tóm tắt báo cáo), nhà thông minh, thành phố thông minh.
Tưởng tượng: Yêu cầu R2 phân tích báo cáo tiếng Trung, tóm tắt tiếng Việt, tạo slide kèm biểu đồ, viết code Python tự động hóa quy trình – tất cả chỉ bằng tiền ly cà phê! Đó là viễn cảnh R2 mạnh và siêu rẻ có thể mang lại. ☕️
6. “Kiến Trúc Sư” Tham Vọng: Đôi Nét Về DeepSeek AI
Đằng sau những model gây chú ý là một công ty đặc biệt:
Nguồn Gốc: Ra đời tháng 7/2023, tách ra từ High-Flyer Quant – quỹ phòng hộ định lượng hàng đầu TQ. High-Flyer là công ty mẹ và nhà đầu tư chính, giúp DeepSeek vượt qua giai đoạn đầu.
Nhà Sáng Lập – Lương Văn Phong (Liang Wenfeng): Sinh năm 1985, nền tảng kỹ thuật, sớm thử nghiệm giao dịch định lượng. Đồng sáng lập High-Flyer, hiện là CEO cả hai. Kín tiếng, “mọt sách” nhưng có tầm nhìn xa. Gốc gác từ quỹ định lượng có thể đã thấm nhuần văn hóa tập trung dữ liệu, hiệu quả, tối ưu thuật toán vào DeepSeek.
Tầm Nhìn Chiến Lược (& Túi Tiền Sâu): High-Flyer đầu tư mạnh vào tính toán từ sớm, tích lũy 10,000 GPU Nvidia A100 trước lệnh cấm vận, xây dựng siêu máy tính riêng. Lợi thế tài chính/phần cứng tạo điều kiện “vườn ươm” lý tưởng, giúp DeepSeek R&D nhanh mà không áp lực vốn. Sau này dùng chip H800 bản xuất khẩu cho V3/R1.
Văn Hóa & Triết Lý: Quản lý phẳng/ngang, khác biệt với công ty TQ khác. Ưu tiên nghiên cứu cơ bản, tiến bộ công nghệ hơn doanh thu. Tham vọng AGI rõ ràng. Tuyển dụng dựa trên kỹ năng, không quá coi trọng kinh nghiệm, chào đón cả người ngoài ngành (thơ ca, toán). Động lực chính là tò mò khoa học.
Cách Tiếp Cận Mở: Hay công bố model mạnh dạng trọng số mở (R1 giấy phép MIT), chia sẻ kỹ thuật qua ArXiv. Thu hút cộng đồng, nhận feedback nhanh, nhưng gây tranh cãi về nguồn mở/đóng. Đối lập với sự khép kín của lab phương Tây, cách này xây dựng thiện chí và phá vỡ mô hình kinh doanh đối thủ.
7. Mạch Đập Cộng Đồng: Bàn Tán Xôn Xao Về R2
Tin đồn về R2 làm cộng đồng AI dậy sóng:
Phản Ứng Tin Rò Rỉ: Reddit, X.com, YouTube tràn ngập thảo luận về tham số khủng, giá rẻ không tưởng, chip Huawei, hiệu năng so với GPT/Claude.
Góc Nhìn Chuyên Gia & Nhà Phân Tích:
Tác Động Thị Trường: Dự đoán R2 phá vỡ thị trường, thách thức Nvidia, buộc đối thủ giảm giá.
Yếu Tố Khác Biệt: Hiệu quả, đổi mới phần mềm của DeepSeek là lợi thế chính.
Hàm Ý Địa Chính Trị: Bằng chứng TQ thu hẹp khoảng cách AI, nỗ lực tự chủ.
Sự Hoài Nghi: Nghi ngờ tính chính xác của chi phí, cần kiểm chứng hiệu năng độc lập.
Việc cộng đồng/phân tích tập trung vào chi phí/hiệu quả cho thấy thị trường có thể đang bão hòa về hiệu năng “đủ tốt”, yếu tố kinh tế ngày càng quan trọng.
Tâm Trạng Chung:
Hào Hứng: Kỳ vọng lớn vào model đột phá, rẻ, (hy vọng) nguồn mở.
Nghi Ngờ: Hoài nghi tin đồn, benchmark, hiệu năng thực tế.
Góc Nhìn Địa Chính Trị: Thảo luận về đua AI Mỹ-Trung, chiến tranh chip. Cho thấy nhận thức tiến bộ công nghệ gắn liền lợi ích quốc gia, chuỗi cung ứng.
Phản ứng cộng đồng như xem ván poker: một người chơi tung bài lạ, có thể thay đổi cục diện, nhưng không ai chắc là thật hay lừa! 🤔
8. Kết Luận: R2 – Cách Mạng, Tin Đồn, Hay Đâu Đó Lưng Chừng?
DeepSeek R2 đang đứng trước sự chú ý toàn cầu với lời hứa hẹn tham vọng: kiến trúc MoE lai tiên tiến, quy mô khủng (1.2T/78B), chi phí siêu rẻ (rẻ hơn 97%?), hiệu năng ngang GPT-4o, năng lực đa phương thức/ngôn ngữ/lập trình mạnh mẽ. Đằng sau là DeepSeek AI – công ty trẻ nhưng đổi mới thần tốc.
NHƯNG, cần nhấn mạnh: Phần lớn thông tin về R2 vẫn là tin đồn chưa kiểm chứng. Cần chờ thông báo chính thức, bài báo kỹ thuật, đánh giá độc lập.
Dẫu vậy, nếu tin đồn phần lớn là thật, R2 có thể tạo bước ngoặt lớn:
Đại chúng hóa sức mạnh AI.
Thúc đẩy đổi mới dựa trên hiệu quả.
Tái định hình cục diện cạnh tranh.
Cột mốc cho AI Trung Quốc.
Ngay cả khi thông số không hoàn toàn đúng, việc DeepSeek có khả năng làm được điều đó (dựa trên thành tích V2/V3/R1) đã là tín hiệu quan trọng: thị trường AI dễ bị phá vỡ hơn bởi người chơi mới, cách tiếp cận mới.
Tóm lại, R2 tiềm năng lớn, nhưng cần thận trọng chờ thông tin chính thức. Hành trình R2, dù đáp ứng được sự cường điệu hay không, chắc chắn sẽ là chương hấp dẫn trong biên niên sử AI. Thế giới AI tiếp tục quay, cùng chờ xem rồng R2 bay cao đến đâu! 🚀