Không có bữa trưa miễn phí — nhưng đôi khi món khai vị cũng đã đủ no.
Khi các trợ lý AI cho lập trình trở thành công cụ thiết yếu với các nhà phát triển, chi phí cho các mô hình cao cấp như Claude 4 Sonnet (hoặc Opus) và GPT-4.1 có thể tích tụ rất nhanh. Với nhiều người, nhất là những ai mới bắt đầu hoặc làm dự án phụ, việc trả hơn 20 USD/tháng để truy cập API có thể là khó khăn. Nhưng nếu tôi nói với bạn rằng có những mô hình mà chi phí chỉ là vài xu — hoặc thậm chí hoàn toàn miễn phí — vẫn có thể xử lý được các tác vụ lập trình thực tế?
Tôi đã dành một tuần để thử nghiệm các mô hình AI lập trình giá phải chăng, để xem chúng so sánh như thế nào với các lựa chọn cao cấp. Kết quả có thể khiến bạn bất ngờ.
Các mô hình hiện đại nhất (SOTA như Claude 4 Sonnet, GPT-4.1 và Gemini Pro 2.5) vẫn là tiêu chuẩn vàng đối với người dùng AI hỗ trợ việc Code, nhưng đã xuất hiện những lựa chọn thực tế có thể xử lý nhiều tác vụ lập trình với chi phí nhỏ hơn rất nhiều.
Trong bài này, tôi so sánh 4 mô hình tiết kiệm chi phí — đồng thời tiến hành thử nghiệm thực tế với việc viết và phân tích code. Các mô hình được đưa vào so sánh theo thứ tự chi phí:
Lưu ý: khi dùng AI cho việc lập trình, đa số token bạn sử dụng là token input (prompt, ngữ cảnh repo, lệnh agent). Phạm vi chi phí từ 7 đến 30 xu cho mỗi triệu token input đã thấp hơn rất nhiều so với các mô hình SOTA:
Mặc dù chúng ta có thể tranh luận về độ khách quan của benchmark hay ứng dụng thực tế của chúng, tôi nghĩ chúng hữu ích khi so sánh mô hình. Bầu không khí (vibes) là một phần của phép đo, nhưng cũng có khác biệt khoa học ảnh hưởng cách mô hình sinh code nhanh và chính xác. Khả năng mà kỹ sư phần mềm sử dụng để đánh giá các khác biệt này sẽ là lợi thế của thế hệ tiếp theo.
Một trong các trang benchmark tôi thích là Artificial Analysis. Tôi đưa vào vài biểu đồ thử nghiệm của các mô hình trong bài này cùng các mô hình SOTA.
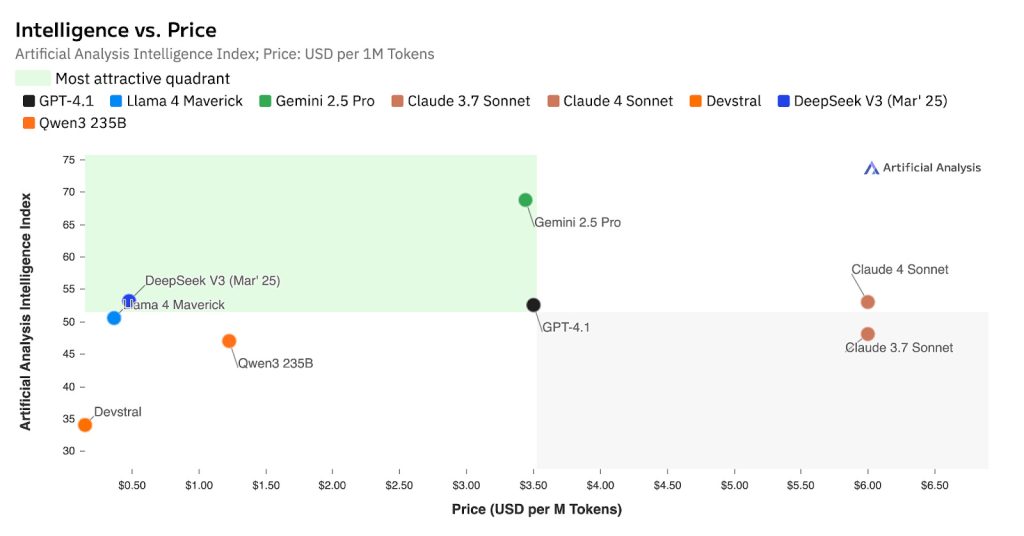
Biểu đồ đầu tiên cho thấy một điều rất thú vị — có một ‘góc phần tư hấp dẫn nhất’ nơi bạn nhận được mức độ thông minh cao với chi phí tương đối thấp. Gemini 2.5 Pro nằm chính xác ở vị trí hoàn hảo này, mang lại trí tuệ ở cấp độ cao cấp với mức giá khoảng 3,50 USD cho mỗi triệu token
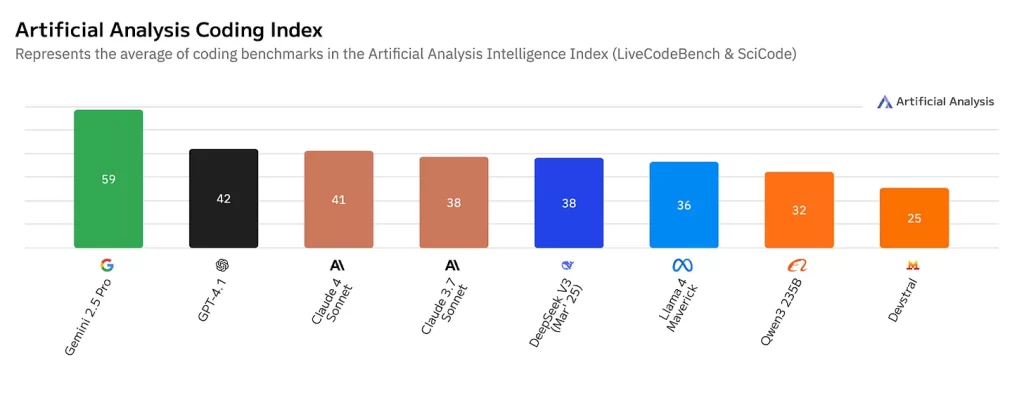
Chỉ số về lập trình cho thấy một bức tranh chi tiết hơn. Gemini 2.5 Pro vượt trội với điểm số 59, nhưng nếu nhìn vào nhóm tầm trung, GPT-4.1, Claude 4 Sonnet, và Claude 3.7 Sonnet đều nằm trong khoảng 38–42. Sau đó, có một sự tụt giảm đáng kể khi chuyển sang nhóm giá rẻ.
Chỉ số trí tuệ tổng hợp cho thấy Gemini 2.5 Pro dẫn đầu với 69 điểm, trong khi nhóm kế tiếp (DeepSeek V3, các mẫu Claude, và GPT-4.1) nằm trong khoảng 48–53 điểm. Các mẫu giá rẻ mà tôi đã thử nghiệm — Qwen3 235B và Devstral — lần lượt đạt 47 và 34 điểm.
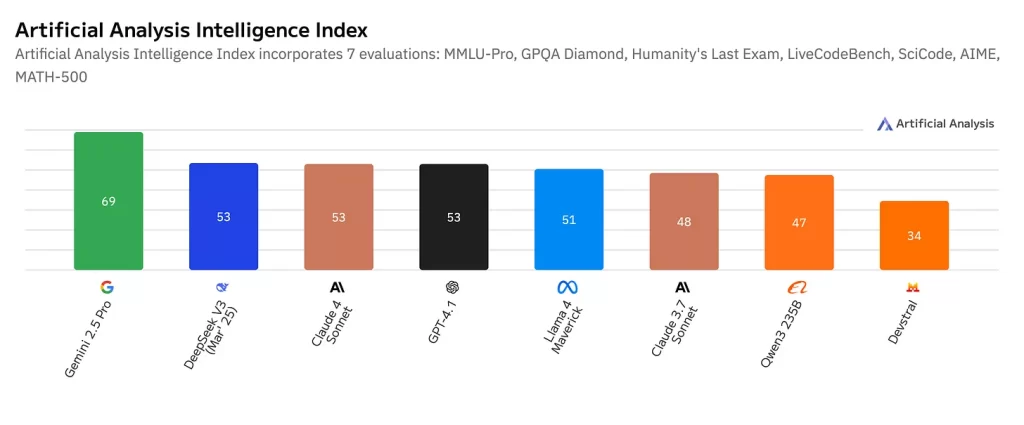
Điểm mấu chốt là thế này: khoảng cách giữa các mô hình cao cấp và giá rẻ thực ra hẹp hơn nhiều so với chênh lệch về giá. Một mô hình đạt 47 điểm so với 69 điểm không hề kém quá xa trong nhiều tác vụ lập trình, nhưng chi phí lại rẻ hơn tới 10 lần.
Dữ liệu này củng cố cho khuyến nghị về phương pháp kết hợp (hybrid) mà tôi nêu ở cuối bài blog. Hãy sử dụng Gemini 2.5 Pro (69 điểm) cho các công việc như lên kế hoạch kiến trúc, nơi mà mức độ thông minh cao thực sự quan trọng; sau đó dùng các mô hình giá rẻ khoảng 47 điểm cho phần triển khai. Cách làm này giúp bạn đạt được 90% hiệu suất với chỉ 20% chi phí.
Tôi chọn 3 thử thách lập trình thực tế:
Kết quả tóm tắt:
Kết quả:
Kết quả (điểm 1–10):
Chiến lược này có thể giảm chi phí 80–90% mà vẫn giữ chất lượng tốt.
You need to login in order to like this post: click here
YOU MIGHT ALSO LIKE

SUBSCRIBE TO OUR NEWSLETTER

