Kafka là gì? Nếu lần đầu bạn nghe đến Kafka thì đừng lo, trong bài viết dưới đây TopDev sẽ giúp bạn cập nhật các kiến thức mới nhất về Kafka và các ứng dụng tuyệt vời của nó. Cùng chúng tôi tìm hiểu ngay nhé!
Kafka với tên gọi đầy đủ là Apache Kafka là hệ thống message pub/sub phân tán mã nguồn mở (distributed messaging system) được phát triển bởi Apache Software Foundation và được viết bằng Java và Scala.
Bên pulbic dữ liệu được gọi là producer, bên subscribe nhận dữ liệu theo topic được gọi là consumer. Kafka có khả năng truyền một lượng lớn message theo thời gian thực, trong trường hợp bên nhận chưa nhận message vẫn được lưu trữ sao lưu trên một hàng đợi và cả trên ổ đĩa bảo đảm an toàn. Đồng thời nó cũng được replicate trong cluster giúp phòng tránh mất dữ liệu.
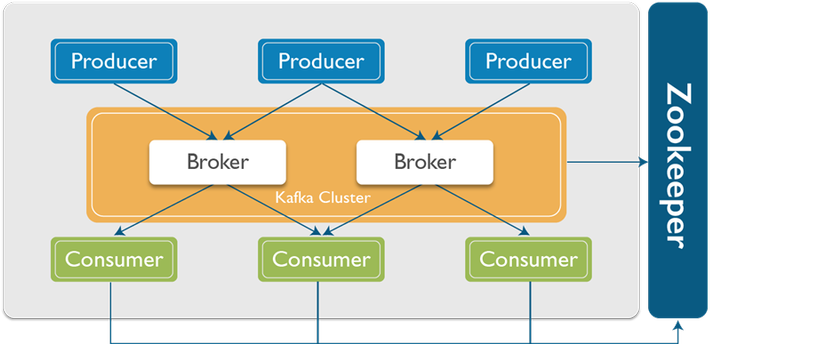
Kafka là gì? – Có thể hiểu là một hệ thống logging để lưu lại các trạng thái của hệ thống đề phòng tránh mất thông tin.
Định nghĩa trên được giải thích bằng các khái niệm sau:
topic, sử dụng producer để publish message vào các topic. Dữ liệu được gửi đển partition của topic lưu trữ trên Broker.consumer để subscribe vào topic, các consumer được định danh bằng các group name. Nhiều consumer có thể cùng đọc một topic.topic được lưu trữ. Một topic có thể có một hay nhiều partition. Trên mỗi partition thì dữ liệu lưu trữ cố định và được gán cho một ID gọi là offset. Trong một Kafka cluster thì một partition có thể replicate (sao chép) ra nhiều bản. Trong đó có một bản leader chịu trách nhiệm đọc ghi dữ liệu và các bản còn lại gọi là follower. Khi bản leader bị lỗi thì sẽ có một bản follower lên làm leader thay thế. Nếu muốn dùng nhiều consumer đọc song song dữ liệu của một topic thì topic đó cần phải có nhiều partition.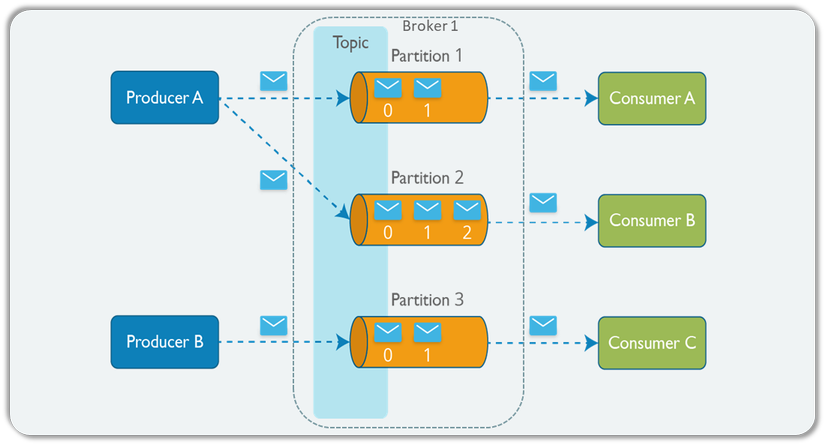
Kafka là dự án opensoure, đã được đóng gói hoàn chỉnh, khả năng chịu lỗi cao, hiệu năng rất tốt và dễ dàng mở rộng mà không cần dừng hệ thống.
Kafka thật sự đáng tin cậy, có khả năng lưu trữ lượng dữ liệu lớn nên nó đang dần được thay thế cho hệ thống message truyền thống.
Một hệ thống thương mại điện tử có nhiều server thực hiện các tác vụ khác nhau. Tất cả các server này đều sẽ giao tiếp với database server để đọc ghi dữ liệu.
Vì vậy sẽ có rất nhiều data pipeline kết nối từ rất nhiều server khác đến database server này. Cơ cấu như sau:
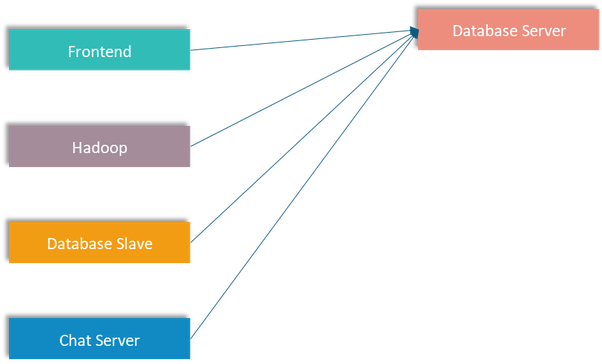
Nhìn đơn giản vậy thôi chứ đây là hệ thống nhỏ, đối với hệ thống lớn hơn thì nó sẽ như vầy:
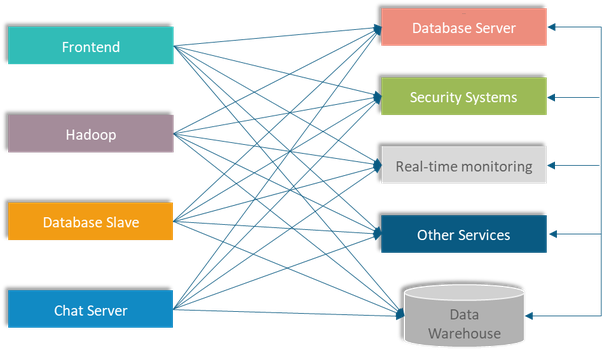
Lúc này data pipeline sẽ phức tạp khủng khiếp do gia tăng lượng hệ thống server. Lúc này nếu ta sử dụng Kafka tách rời các data pipeline giữa các hệ thống để làm cho việc giao tiếp giữa các hệ thống trở nên đơn giản hơn và dễ quản lý hơn.
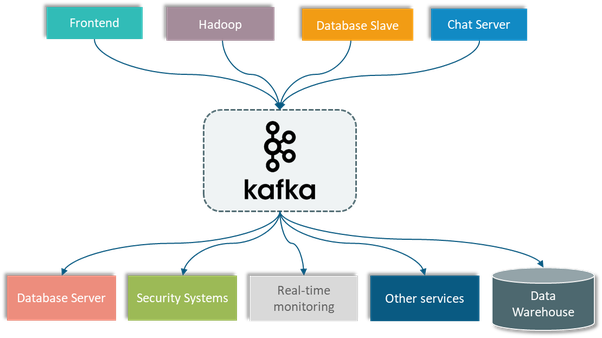
Tổng kết lại, Apache Kafka là một hệ thống hoàn hảo để xử lý các khối dữ liệu khổng lồ và phức tạp. Hi vọng bài viết trên của đội ngũ TopDev có thể giúp bạn hiểu rõ khái niệm cũng như các tính năng nổi bật của Kafka, từ đó ứng dụng vào mô hình triển khai một cách phù hợp nhất.
You need to login in order to like this post: click here
YOU MIGHT ALSO LIKE

SUBSCRIBE TO OUR NEWSLETTER

