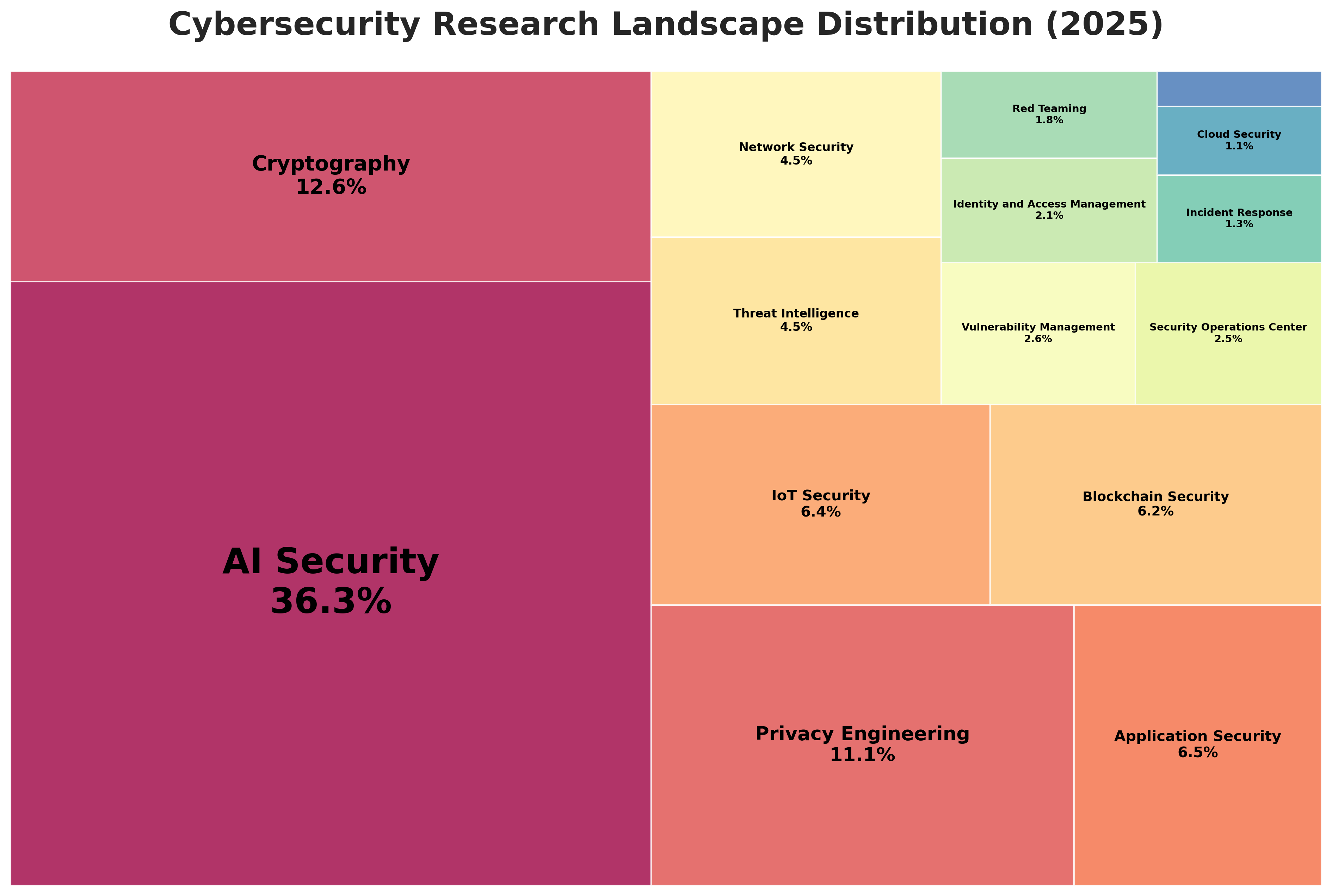
Đánh giá hiệu năng toàn diện: GPT-5.1 vs Gemini 3.0 vs Opus 4.5
Ba gã khổng lồ AI đã phát hành các mô hình lập trình tốt nhất của họ trong cùng một tháng. Đây là thời điểm chưa từng có. Thay vì chạy các bài kiểm tra điểm chuẩn (benchmark) tổng hợp—thứ thường không phản ánh đúng thực tế—chúng tôi đã chạy ba mô hình này qua ba kịch bản lập trình thực tế (real-world scenarios) để xem chúng thực sự hoạt động như thế nào khi xây dựng sản phẩm.
- November 12: OpenAI released GPT-5.1 and GPT-5.1-Codex-Max simultaneously
- November 18: Google released Gemini 3.0, a significant upgrade from Gemini 2.5
- November 24: Anthropic released Opus 4.5
Các bài kiểm tra (The Tests)
Chúng tôi thiết lập các bài kiểm tra dựa trên những gì một kỹ sư phần mềm thực thụ phải đối mặt hàng ngày:
- Tuân thủ Prompt (Prompt Adherence): Chúng tôi yêu cầu viết một bộ giới hạn tốc độ (rate limiter) bằng Python với 10 yêu cầu cụ thể (tên lớp chính xác, định dạng thông báo lỗi cụ thể, cấu trúc file, v.v.).
- Mục đích: Kiểm tra xem mô hình có tuân thủ hướng dẫn nghiêm ngặt hay chỉ coi chúng là “gợi ý” và tự ý làm theo cách của mình.
- Tái cấu trúc mã (Code Refactoring): Chúng tôi đưa cho các mô hình một API TypeScript cũ (legacy), lộn xộn với các lỗ hổng bảo mật và các thực hành xấu (bad practices).
- Mục đích: Xem liệu chúng có phát hiện ra vấn đề, sửa chữa kiến trúc hay không, và liệu chúng có chủ động thêm các biện pháp bảo vệ (safeguards) mà chúng tôi không yêu cầu rõ ràng hay không.
- Mở rộng hệ thống (System Extension): Chúng tôi cung cấp một phần mã nguồn của hệ thống thông báo (notification system) và yêu cầu chúng giải thích kiến trúc trước, sau đó thêm một trình xử lý email (email handler) mới vào đó.
- Mục đích: Kiểm tra khả năng hiểu ngữ cảnh hệ thống (comprehension) trước khi thực thi mã.
Kết quả chi tiết (The Results)
Bài kiểm tra 1: Tuân thủ Prompt (Python Rate Limiter)
Kết quả bài test này cho thấy sự khác biệt rõ rệt về “tính cách” của từng mô hình:
- Gemini 3.0: Tuân theo hướng dẫn đúng nghĩa đen nhất (Literally). Nó thực hiện chính xác từng chút một những gì được yêu cầu. Nếu prompt bảo đặt tên biến là
X, nó sẽ là X. Không thừa, không thiếu.
- Opus 4.5: Bám sát thông số kỹ thuật (spec) rất tốt, đồng thời tạo ra tài liệu hướng dẫn (docs) sạch sẽ hơn so với Gemini.
- GPT-5.1: Chuyển sang chế độ “phòng thủ” (defensive mode). Nó đã thêm vào các logic xác thực (validation) và các biện pháp bảo vệ (safeguards) mà chúng tôi không yêu cầu. Mặc dù code tốt hơn về mặt kỹ thuật, nhưng nó đã thất bại trong việc tuân thủ “nguyên văn” yêu cầu của đề bài.
Bài kiểm tra 2: Tái cấu trúc mã (TypeScript API)
Đây là bài kiểm tra khó nhằn nhất và kết quả rất thú vị:
- Opus 4.5: Chiến thắng áp đảo. Nó đưa ra bản tái cấu trúc hoàn chỉnh nhất (đạt 10/10 yêu cầu). Code đầu ra rất sạch, hiện đại và xử lý được toàn bộ các vấn đề của code cũ.
- GPT-5.1: Đạt 9/10. Điểm mạnh nhất của GPT là khả năng phát hiện lỗi bảo mật. Nó bắt được các vấn đề như thiếu xác thực (missing auth) và các thao tác DB không an toàn. Tuy nhiên, nó hơi dài dòng.
- Gemini 3.0: Đạt 8/10. Nó đưa ra output sạch và nhanh hơn, nhưng đã bỏ lỡ một số lỗi kiến trúc tiềm ẩn (architectural flaws) quan trọng.
Bài kiểm tra 3: Mở rộng hệ thống (Notification System)
- Opus 4.5: Một lần nữa thể hiện tư duy kiến trúc sư. Nó đưa ra giải pháp hoàn chỉnh nhất với các templates (mẫu) cho từng loại sự kiện (event type).
- GPT-5.1: Đi rất sâu vào giai đoạn tìm hiểu (understanding phase). Nó xác định các bug tiềm năng, thậm chí tạo ra sơ đồ (diagrams) để giải thích luồng dữ liệu, sau đó xây dựng các tính năng phong phú như CC/BCC và tệp đính kèm. Nó viết code nhiều hơn mức cần thiết khoảng 1.5 đến 1.8 lần so với Gemini.
- Gemini 3.0: Hiểu được những điều cơ bản nhưng chỉ đưa ra phiên bản “tối thiểu” (bare minimum) để code chạy được.
Phân tích Tốc độ & Chi phí (Speed & Cost Analysis)
Ngoài chất lượng code, chúng tôi cũng đo lường hiệu quả hoạt động:
- Claude Opus 4.5:
- Tốc độ: Nhanh nhất tổng thể (hoàn thành task phức tạp trong 7 phút).
- Chi phí: Đắt nhất ($1.68 cho bài test hệ thống). Tuy nhiên, nếu bạn cần code chạy được ngay lần đầu tiên (one-shot), mức giá này là xứng đáng.
- Gemini 3.0:
- Tốc độ: Có độ trễ khi “suy nghĩ” (thinking process) ở các tác vụ phức tạp, dù output ngắn hơn.
- Chi phí: Rẻ nhất ($1.10). Tuy nhiên, trong task hệ thống phức tạp, chi phí thực tế lại cao hơn dự kiến do nó tốn nhiều token cho việc suy luận ngầm.
- GPT-5.1:
- Đặc điểm: Viết code dài hơn 1.5x – 1.8x so với Gemini (do thêm JSDoc, Validation, Error Handling). Điều này làm tăng chi phí token đầu ra nhưng code an toàn hơn.
Tổng kết: Nên chọn ai? (Takeaways)
Cuộc chiến này không có kẻ thắng người thua tuyệt đối, nó phụ thuộc vào mục đích sử dụng của bạn:
- Chọn Claude Opus 4.5 cho CHIỀU SÂU (Depth): Nếu bạn cần xử lý context dài, lập kế hoạch dài hạn, và suy luận logic phức tạp. Đây là mô hình tốt nhất để đóng vai trò “Kiến trúc sư trưởng”. Code của Opus thường “đúng ngay lần đầu”.
- Chọn Gemini 3.0 cho CHIỀU RỘNG (Breadth): Với cửa sổ ngữ cảnh 1M token và khả năng tích hợp Google Search, đây là lựa chọn tốt nhất cho việc tra cứu, tích hợp kiến thức thực tế và các tác vụ đa phương thức.
- Chọn GPT-5.1 cho SỰ LINH HOẠT (Flexibility): Nó cân bằng giữa tốc độ và độ sâu. GPT-5.1 cực kỳ mạnh trong việc sử dụng công cụ (tool use) và có một “tính cách” tùy biến cao. Đặc biệt, nếu bạn quan tâm đến bảo mật (security), GPT-5.1 là người soi lỗi tốt nhất.
Lưu ý: Các mô hình AI thay đổi rất nhanh. Bài đánh giá này dựa trên các phiên bản mới nhất tính đến thời điểm viết bài.
(Bài viết được lược dịch từ https://blog.kilo.ai/p/benchmarking-gpt-51-vs-gemini-30-vs-opus-45)
You need to login in order to like this post: click here

Mar 31, 2026
Mar 31, 2026