Bạn đã test xong, CI/CD xanh lá, deploy lên production — rồi 2 tiếng sau user báo lỗi. Quen không? Vấn đề không phải bạn test thiếu, mà bạn đang test sai thứ. Observability-driven QA là cách tester dùng chính dữ liệu production để biết test cái gì thực sự quan trọng — trước khi bug tìm đến bạn.

Hãy thành thật mà nói — bao nhiêu lần bạn pass hết test, deploy lên production, rồi 3 tiếng sau nhận Slack từ khách hàng báo lỗi?
Đó không phải lỗi của bạn. Đó là vấn đề cấu trúc.
Test truyền thống hoạt động trong môi trường giả định: data sạch, flow rõ ràng, user hành xử như spec. Nhưng production thì khác. Production behavior đã trở thành nguồn sự thật quan trọng nhất cho testing — những vấn đề như performance bottleneck dưới tải cao hay UX challenge trên từng geography khác nhau thường không xuất hiện trong môi trường test có kiểm soát.
Và trong 2026, testing không còn là bước cuối — QA được tích hợp xuyên suốt mọi giai đoạn phát triển, shift-left và shift-right song song, với real-time production monitoring đảm bảo release an toàn hơn.
Observability-driven QA ra đời từ thực tế đó.
Nói đơn giản: dùng dữ liệu production để dẫn dắt chiến lược testing, thay vì chỉ dựa vào spec và assumption.
Ba trụ cột cốt lõi:
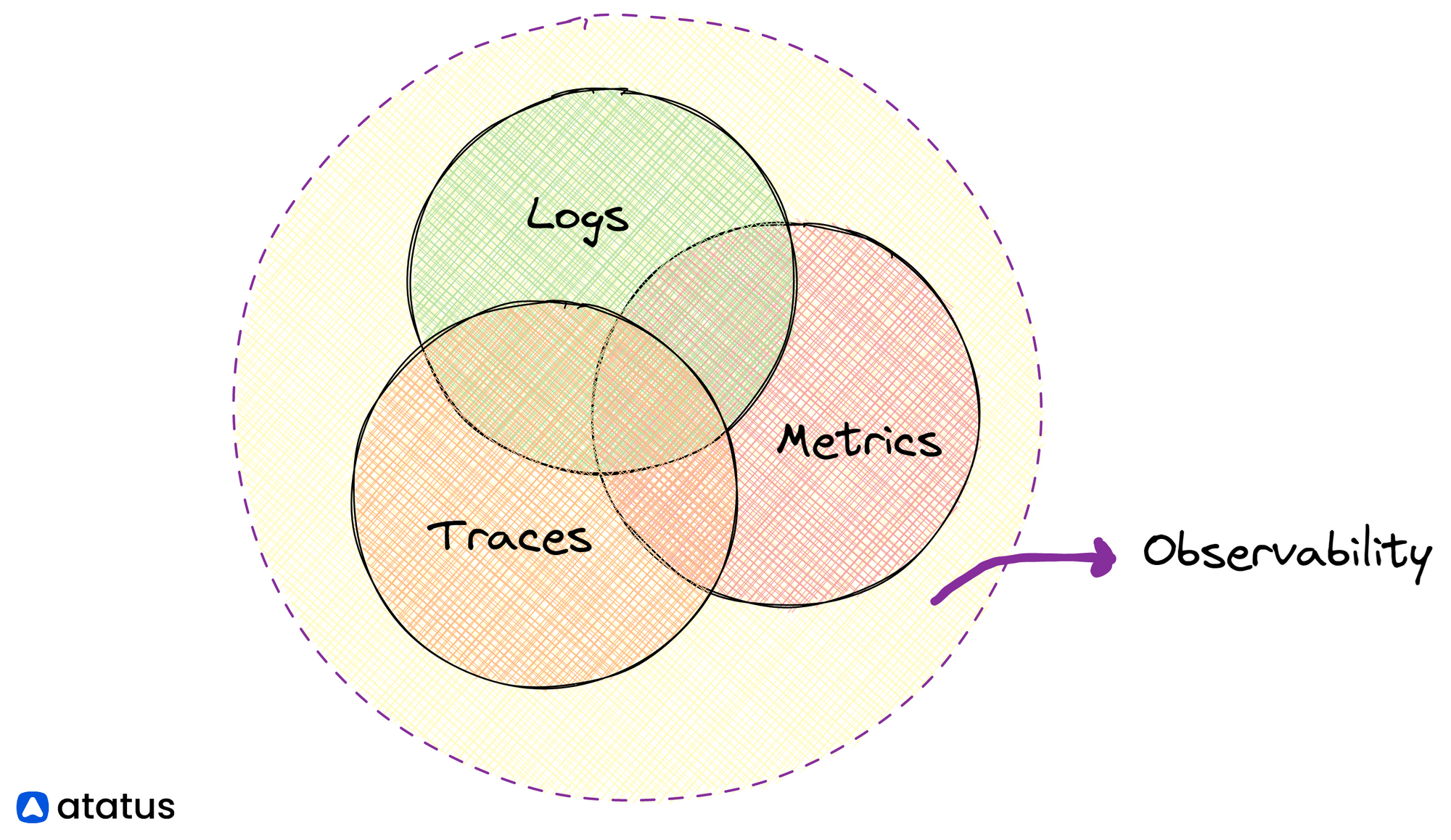
Logs — Không phải log để debug sau khi crash. Mà là structured logs giúp bạn thấy user thực sự đang làm gì, flow nào bị drop, error nào xuất hiện lặp lại.
Metrics — Error rate, latency p95, throughput. Alerting threshold được định nghĩa cho error rate spikes, response time degradation, resource utilization anomalies — tất cả là continuous quality signal.
Traces — Distributed tracing theo dõi một request xuyên suốt toàn bộ hệ thống. Khi một user action mất 4 giây, trace cho bạn biết chính xác 4 giây đó “rơi” vào service nào.
Khi có đủ ba thứ này, bạn không còn đoán mò để viết test. Bạn nhìn vào data và biết test cái gì trước, test ở đâu, và bao giờ cần alert.
Đây là flow mà các team đang áp dụng hiệu quả:
Production Signal → Phân tích → Tạo/Cập nhật Test → Đưa vào CI/CDBước 1 — Thiết lập observability baseline Trước khi viết thêm một test case nào, hãy đảm bảo bạn có dashboard theo dõi: error rate theo endpoint, latency p50/p95/p99, và top 10 error messages mỗi ngày.
Bước 2 — Đọc log như đọc test case Mỗi tuần dành 30 phút review production logs. Tìm pattern: flow nào user hay abandon? API nào timeout nhiều nhất? Error message nào lặp lại? Đây chính là test case bạn chưa viết.
Bước 3 — Map signal vào test
| Production signal | Test action |
|---|---|
API /payment timeout 3% requests |
Thêm performance test với concurrent load |
Error NullPointerException ở checkout |
Thêm edge case: cart rỗng, session expired |
| User drop-off tại step 3 onboarding | Thêm exploratory test cho UX flow |
| Latency tăng đột biến sau deploy | Thêm smoke test latency vào CI/CD gate |
Bước 4 — Đưa quality gate vào pipeline Thay vì ship dựa trên “all tests green”, hãy gate release dựa trên risk threshold — kết hợp historical data, test coverage, change velocity và defect trends.
Observability-driven QA không yêu cầu bạn trở thành SRE hay DevOps. Nhưng cần thêm một vài kỹ năng:
Biết đọc dashboard — Grafana, Datadog, hay bất kỳ tool nào team bạn đang dùng. Không cần setup, nhưng cần biết đọc và đặt câu hỏi đúng.
Hiểu cơ bản về log structure — JSON log, correlation ID, trace ID. Khi bạn thấy một error trong log, bạn cần biết cách lần theo trace ID để hiểu toàn bộ context.
Tư duy risk-based — Enterprises nên đo confidence và risk exposure thay vì raw test coverage. Metrics gắn với system reliability, production behavior, và business impact cho signal rõ ràng hơn về sự sẵn sàng của hệ thống.
Collaborate với SRE/DevOps — Hỏi họ: “Alert nào đang trigger nhiều nhất tuần này?” Câu trả lời đó chính là backlog testing của bạn.
Takeaway: Observability không thay thế testing — nó làm testing thông minh hơn. Monitor trước để biết test cái gì. Test đúng thứ để monitor ít alarm hơn. Vòng lặp đó, khi chạy tốt, là lúc QA thực sự trở thành quality engineering.
You need to login in order to like this post: click here
YOU MIGHT ALSO LIKE

