Một hệ thống back-end dù code tốt đến đâu cũng sẽ có lỗi.
Và khi có lỗi, log là “ánh sáng duy nhất” giúp dev lần ra nguyên nhân.
Tuy nhiên, thực tế rất nhiều team chỉ dừng lại ở error_log() hoặc console.log() mà chưa có hệ thống logging và monitoring đúng nghĩa.
Bài viết này sẽ giúp bạn hiểu:
Vì sao logging quan trọng.
Cách thiết kế hệ thống log tốt.
Những công cụ nên dùng để monitor ứng dụng hiệu quả.
Log không chỉ để “debug khi có lỗi”, mà còn để:
Phân tích hành vi người dùng (ví dụ: họ dùng API nào nhiều nhất).
Theo dõi hiệu năng (API nào chậm, tần suất request tăng bất thường).
Giám sát bảo mật (phát hiện truy cập trái phép, brute force).
Phục vụ audit / compliance (ghi lại lịch sử thao tác, dữ liệu nhạy cảm).
Nói cách khác: log là trí nhớ dài hạn của hệ thống.
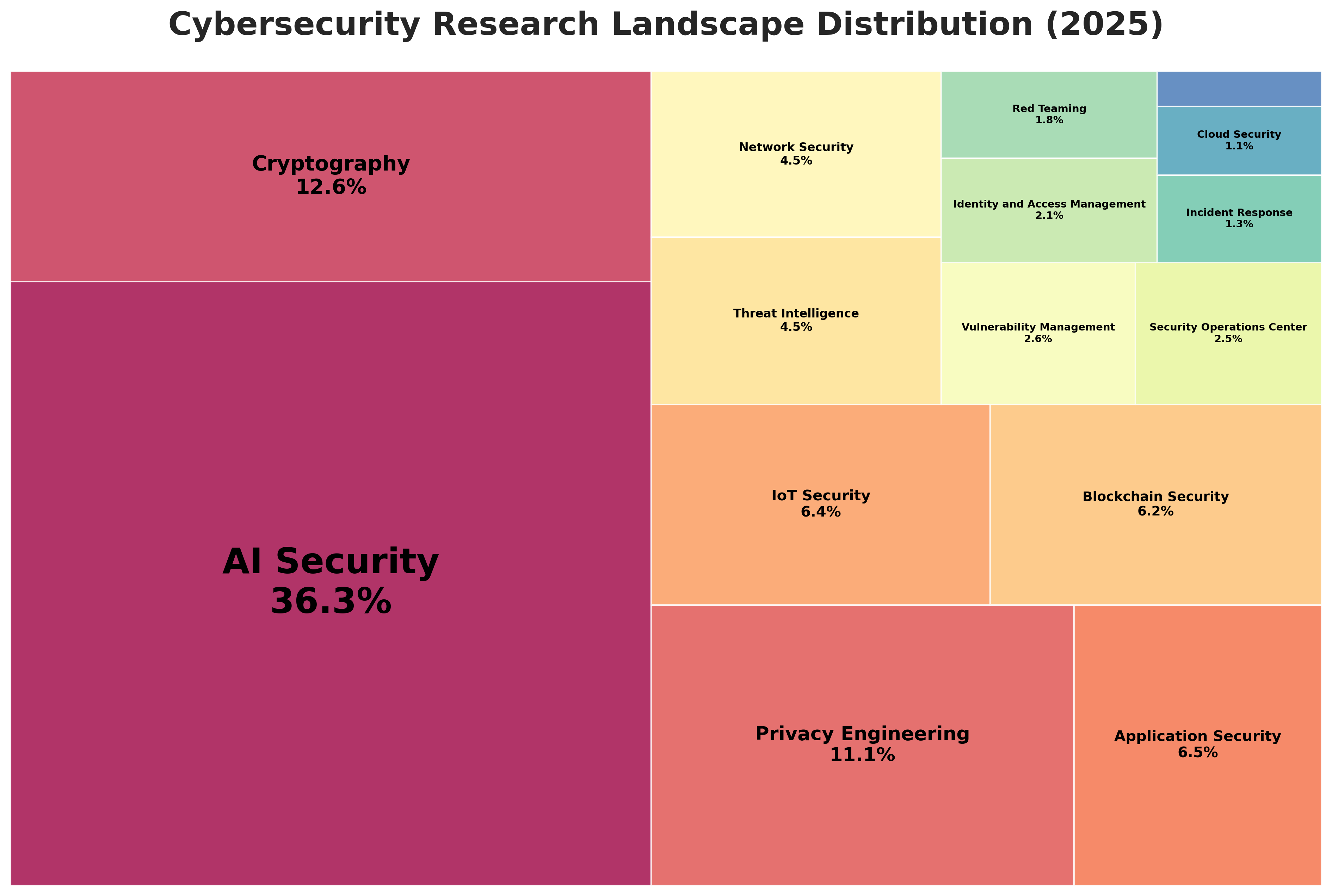
| Loại log | Mục đích | Ví dụ |
|---|---|---|
| Application log | Theo dõi hoạt động của ứng dụng | “User A created order #123” |
| Access log | Theo dõi request từ client | IP, route, method, response time |
| Error log | Ghi lại lỗi hệ thống hoặc exception | “DB connection timeout” |
| Audit log | Theo dõi hành vi thay đổi dữ liệu | “Admin B deleted user #5” |
| Performance log | Theo dõi metric hệ thống | Response time, CPU, memory usage |
Một log tốt phải có cấu trúc rõ ràng để dễ phân tích (nhất là khi bạn dùng các công cụ như ELK hoặc Datadog).
Ví dụ JSON log chuẩn:
Một số nguyên tắc:
Luôn có timestamp theo UTC.
Log theo level: debug, info, warning, error, critical.
Dùng trace_id để theo dõi luồng request xuyên qua nhiều service.
Tránh log dữ liệu nhạy cảm (password, token, credit card).
Dễ setup, dùng cho ứng dụng nhỏ.
Dạng: /var/log/app.log, storage/logs/laravel.log.
Dễ mất khi container restart → không phù hợp cho hệ thống lớn.
Khi có nhiều server/service, log cần được thu thập về một nơi.
Kiến trúc phổ biến:
App → Log shipper → Log storage → Visualization tool
Ví dụ stack phổ biến:
ELK Stack (Elasticsearch + Logstash + Kibana)
EFK Stack (Elasticsearch + Fluentd + Kibana)
Graylog, Datadog, Splunk, AWS CloudWatch
Sơ đồ tổng quát:
Logging giúp “điều tra sau khi lỗi xảy ra”, còn Monitoring giúp “phát hiện lỗi ngay khi nó bắt đầu”.
System metrics: CPU, RAM, disk, network.
Application metrics: request count, response time, error rate.
Business metrics: số order, user active, failed transaction.
Prometheus + Grafana – open-source, dễ setup.
Datadog, New Relic, AWS CloudWatch, Sentry – enterprise.
Ví dụ dashboard Grafana:
| Metric | Mục tiêu | Cảnh báo khi |
|---|---|---|
| Response time | < 500ms | > 1s trong 5 phút |
| Error rate | < 1% | > 5% trong 10 phút |
| Memory usage | < 80% | > 90% liên tục 3 phút |
Kết hợp monitoring với alert, bạn có thể:
Gửi thông báo Slack khi lỗi tăng đột biến.
Gửi email/SMS khi API bị downtime.
Tự động tạo ticket Jira cho sự cố nghiêm trọng.
Ví dụ:
“Error rate > 5% trong 10 phút ở service payment-api” → Tự động ping team back-end trên Slack.
✅ Dùng format log thống nhất (JSON, UTC time).
✅ Gắn trace_id cho mọi request (có thể dùng middleware).
✅ Không log data nhạy cảm.
✅ Tạo dashboard riêng cho error & performance.
✅ Tự động xoá log cũ để tiết kiệm storage (log retention).
✅ Test alert thường xuyên để đảm bảo hoạt động.
“Không có log, bạn chỉ đang đoán.”
Logging & monitoring không phải là “việc phụ” – nó là phần cốt lõi giúp hệ thống vận hành ổn định, giúp dev phản ứng nhanh khi có sự cố.
Hãy bắt đầu đơn giản:
Ghi log chuẩn cấu trúc.
Gom log về một nơi.
Tạo dashboard giám sát.
Và khi hệ thống lớn dần, bạn sẽ cảm nhận được giá trị thực sự của việc có một hệ thống logging & monitoring tốt.
You need to login in order to like this post: click here
YOU MIGHT ALSO LIKE

SUBSCRIBE TO OUR NEWSLETTER