

この投稿は、コンピューター・ビジョンの基礎技術を紹介する記事の一つです。
Bài viết này nằm trong chuỗi bài giới thiệu công nghệ xử lý hình ảnh thông minh hay gọi là thị giác máy học (Computer Vision).
コロナ禍が始まってから、感染状況をマネージメントすることがチャレンジになりました。コンピュータービジョンの技術を活かし、人々の間の距離を推定し、決めた半径に近づいてしまうと、警告を出すというSocial Distancing Management (SDM)の応用も急に重要になっています。本稿では、SDMを実装するためのコンピュータービジョンの基礎技術である物体検出とキャリブレーションを紹介します。最後に、実際に動けるデモを紹介します。
Trong thời đại COVID-19, việc kiểm soát và ngăn chặn tình trạng bệnh dịch lây lan trong cộng đồng là một thách thức cần được xử lý. Sử dụng triệt để công nghệ Computer Vision, việc ước lượng khoảng cách giữa mọi người trong đám đông và lên cảnh báo kịp thời khi có hai người gần nhau hơn khoảng cách cho phép là khả thi. Công nghệ này gọi là quản lý khoảng cách xã hội (Social Distancing Management hay SDM). Trong bài viết này, chúng tôi giới thiệu công nghệ cơ bản để thực thi SDM như xác định và nhận dạng vật thể (object detection) cũng như công nghệ photoshop để cân chỉnh hình ảnh (image calibration). Cuối cùng, chúng tôi giới thiệu một demo nhỏ của công nghệ SDM.

Gói công nghệ xác định và nhận diện hình ảnh (Object Detection) là một công nghệ truyền thống, kết hợp cả hai lĩnh vực xử lý ảnh truyền thống (Image Processing, Computer Vision) và máy học (Machine Learning). Vì vậy, nó cũng thường được gọi là công nghệ con của CVML (Computer Vision and Machine Learning). Nền tảng của công nghệ Object Detection bắt đầu được đặt ra từ khá lâu, nhưng 1 bước tiến quan trọng (trước deep learning) chính là thuật toán nhận dạng khuôn mặt của Viola và Jones vào năm 2001.Gói công nghệ xác định và nhận diện hình ảnh (Object Detection) là một công nghệ truyền thống, kết hợp cả hai lĩnh vực xử lý ảnh truyền thống (Image Processing, Computer Vision) và máy học (Machine Learning). Vì vậy, nó cũng thường được gọi là công nghệ con của CVML (Computer Vision and Machine Learning). Nền tảng của công nghệ Object Detection bắt đầu được đặt ra từ khá lâu, nhưng 1 bước tiến quan trọng (trước deep learning) chính là thuật toán nhận dạng khuôn mặt của Viola và Jones vào năm 2001.
Chúng ta cũng trình bày ngắn gọn về công nghệ CVML nhận diện khuôn mặt của Viola và Jones (2001) như sau: Viola-Jones là thuật toán ML dựa trên nội dung (content-based method). Có hai nguồn nội dung đóng góp cho việc học của thuật toán đó là hình ảnh dương (positive, chứa mặt người) và hình ảnh Âm (negative, không chứa mặt người). Dựa vào các kernel định nghĩa sẵn, model sẽ học được một tập đặc trưng có ích nhất cho việc nhận dạng khuôn mặt trong ảnh. Tuy nhiên, cũng như mọi content-based method khác, đặc điểm của Viola-Jones là đòi hỏi domain knowledge (kiến thức sâu về lĩnh vực hình ảnh đã chọn). Ví dụ, với domain ảnh khuôn mặt, việc lựa chọn dữ liệu training positive và negative ảnh hưởng tới chất lượng của model Viola-Jones. Ngoài ra, vì là học theo content nên Viola-Jones có khuynh hướng tìm kiếm ra một bộ đặc trưng khá lớn. Ví dụ, bộ đặc trưng 160000 đặc trưng là chuyện thường thấy với Viola-Jones. Để giảm thiểu số chiều của không gian đặc trưng, một phương pháp đơn giản là dùng thuật toán AdaBoost. Cũng do kiến thức domain cần có, nên thuật toán Viola-Jones thường dùng trong những domain đã chứng tỏ thành công lớn như mặt người. Một chương trình sử dụng OpenCV để nhận dạng khuôn mặt:
def detectAndDisplay(frame, face_cascade):
"""
frame: hình ảnh đầu vào
face_cascade: instance chứa hàm detectMultiScale() để nhận dạng khuôn mặt bằng thuật toán Viola-Jones
"""
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
frame_gray = cv2.equalizeHist(frame_gray)
#-- Thực hiện nhận dạng khuôn mặt trên nhiều kích cỡ (scale) khác nhau
faces = face_cascade.detectMultiScale(frame_gray)
for (x,y,w,h) in faces:
center = (x + w//2, y + h//2)
frame = cv2.ellipse(frame, center, (w//2, h//2), 0, 0, 360, (0, 255, 0), 40)
faceROI = frame_gray[y:y+h,x:x+w]
#-- Nhận dạng mặt và hai mắt dựa trên đặc trưng Haar
eyes = eyes_cascade.detectMultiScale(faceROI)
#-- Hiển thị khu vực mặt và mắt trên hình ảnh
for (x2,y2,w2,h2) in eyes:
eye_center = (x + x2 + w2//2, y + y2 + h2//2)
radius = int(round((w2 + h2)*0.25))
frame = cv2.circle(frame, eye_center, radius, (255, 0, 0 ), 4)
cv2.imshow('Capture - Face detection', frame)
return frame, faces
Lịch sử của CVML gần đây chứng kiến khá nhiều thành tựu trong đến từ công nghệ deep learning và Object Detection cũng không phải ngoại lệ. Như CVML truyền thống mà đại diện là thuật toán Viola-Jones, việc thiết kế đặc trưng là (1) hand-crafted và (2) đòi hỏi kiến thức domain. Deep Learning (DL) giải quyết hai vấn đề này khá tốt. Lợi ích lớn nhất của các thuật toán DL là dựa trên lượng dữ liệu training lớn mà loại bỏ và tự động hóa hoàn toàn quy trình thiết kế vector đặc trưng. Song song với đó, kiến thức của 1 lĩnh vực (domain) cụ thể là không cần thiết, vì model DL sẽ tự động học từ dữ liệu lớn, và trích xuất ra đặc trưng tốt nhất với cấu hình cho sẵn. Ngắn gọn là nếu như CVML truyền thống như Viola-Jones là những model đòi hỏi kiến thức domain sâu thì DL models là những model khởi đầu không biết gì nhưng học và bắt chước nhanh chóng, và giá trị của những models ấy là tự động hóa đa lĩnh vực (đa domain). Nói chung 1 bên thì là có sẵn, 1 bên là sao chép nhanh, cả 2 bên đều có lợi và thành công.
Vậy DL models đã học hỏi như thế nào? Chúng ta sẽ khái lược về các dòng chính của model DL cho object detection và nhìn thấy nhiều lợi ích khác của chúng như đa tác vụ (multi-task learning) với độ chính xác cao. Có 2 dòng chính mà chúng ta quan tâm: (1) Two-Stage models (đại diện chính là Faster R-CNN và FPN); và (2) One-stage models (đại diện là SSD và YOLOvx). Trước hết cũng cần giới thiệu sơ lược về cách hoạt động của deep learning model tổng quan.

Khi tác vụ chỉ có 1 domain cần quan tâm duy nhất (ví dụ mặt người), thì model chỉ cần quan tâm đến duy nhất việc lựa chọn dữ liệu hợp lý (dương và âm) để train domain đó, và thiết kế đặc trưng hợp lý để adapt vào domain đó. Đó là việc CVML truyền thống đã làm tốt. Tuy nhiên, khi phải học cùng lúc khoảng 1000 domain khác nhau, giả định chỉ 1 task duy nhất, và cần có những giới hạn lên không gian đặc trưng, thì DL sẽ là lựa chọn tốt hơn. Một DL model bao gồm nhiều “block” được gọi là các layer, mà mỗi layer có khả năng thực hiện một tác vụ nào đó như convolution, pooling hay activations. Nghe thì có vẻ giống Multi-Layer Perceptron (MLP) nhưng sự khác biệt lớn là DL models có dùng activations như tanh, softmax, .etc. Chính nhờ những activation phi tuyến này, hơn là những hàm tuyến tính, DL models có khả năng học được những domain phi tuyến (khác biệt). Những domain phi tuyến này là hoàn toàn có thể xảy ra khi model phải học tổng hợp cùng lúc 1000 domain nhỏ khác nhau (mà hợp lại là một domain phi tuyến phức tạp, tuy nhiên như đã nói DL models cũng không cần thiết quan tâm tới sự phức tạp ấy). Dựa vào một hàm loss được thiết kế dựa trên chức năng hơn là kiến thức domain (tức là nhà thiết kế hàm loss không cần có kiến thức domain để thiết kế hàm loss tốt), việc học của DL models được chuẩn hóa qua một quy trình gọi là back-propagation (BP). Nội dung tác vụ của 1 layer (block) có thể là xử lý ảnh như convolution hay xử lý âm thanh, dữ liệu text hay xử lý số liệu thông thường tùy vào bài toán. Ngoài ra còn các tricks khác trong training deep models mà các bạn có thể tìm hiểu thêm qua tập san các hội nghị chuyên sâu như ICLR hay NIPS. Tuy nhiên, chúng tôi trình bày khái niệm tổng quan đây để chuyển tiếp sang giới thiệu tiếp. Tóm tắt, các bạn có thể hiểu một DL model như 1 “workflow” bao gồm nhiều block mà sau khi thực hiện xong tác vụ của block này, output của block đó sẽ được dùng làm input của các block khác.
Việc thiết kế block diagram cho DL model đòi hỏi kiến thức của lĩnh vực lớn hơn domain nhỏ. Tuy nhiên, trong bài toán object detection có sẵn một số “templates”. Đó chính là hai dòng model mà chúng ta sẽ nhắc đến sau đây. Object detection thực ra là 1 multi-task learning framework, trong đó, ít nhất hai tác vụ được học song song: (1) tác vụ phát hiện các vật thể và (2) phân loại các vật thể đã phát hiện. Tác vụ (1) sẽ sinh ra một mảng N x 4 có dạng [x, y, h, w] chứa thông tin khung hình của vật thể trong ảnh. Tác vụ (2) ứng với mỗi output của tác vụ (1) sẽ gắn cho khung hình nhỏ 1 nhãn thể hiện lĩnh vực (domain) của vật thể được phát hiện như cat, dog, person, … Học tác vụ (1) đòi hỏi khả năng hồi quy (regression) giữa vật thể model phát hiện ra và các vật thể thực có trong hình ảnh. Học tác vụ (2) đòi hỏi khả năng phân loại (classification) đúng trên từng lĩnh vực nhỏ (như lĩnh vực dog, lĩnh vực cat, lĩnh vực person, …). Do vậy thiết kế hàm loss của mỗi tác vụ có khác nhau phân thành regression loss và classification loss. Tuy vậy, ở output cuối cùng, chúng ta dùng hàm tổng của hai loss có nhân trọng số để tính loss tổng cho back propagation. Thiết kế hàm loss cho classification thường có tính trên output sau activation để đảm bảo cover tất cả các lĩnh vực con. Hơn nữa việc học có thể tách riêng classifier ra để học ví dụ âm và ví dụ dương như trong Fast R-CNN. Nhìn qua thì thấy có vẻ tác vụ (2) phải đợi tác vụ (1) xong thì mới thực hiện, nhưng phần lớn các pipelines có sử dụng deep learning gần đây đã tiến tới song song hóa cả 2 tác vụ này. Việc naỳ được thực hiện nhờ một tầng trung gian, không output ra tọa độ khung hình hay nhãn của lĩnh vực mà chỉ output ra 1 vector đặc trưng trung gian (256 chiều) và sử dụng đặc trưng đó để học song song hai nhánh.
Two-stage detectors như Faster R-CNN và FPN chia quy trình làm hai bước độc lập, bước đầu là dùng một model có sẵn để trích xuất ra đặc trưng trung gian 256 chiều, sau đó bước 2 là học song song cả regression và classification sử dụng 1 custom block là Region Proposal Network (RPN). FPN thì thay vì sử dụng 1 vector đặc trưng 256 chiều duy nhất thì sử dụng một pyramid (kim tự tháp) gồm nhiều tầng đặc trưng với số chiều riêng biệt. Kết hợp kết quả dự đoán của các tầng khác nhau trong Kim tự tháp đặc trưng, kết quả của cả hai nhánh regression và classification đều được nâng cao với budget time tương tự. One-stage detectors như SSD hay anh em họ YOLO thường được dùng gần đây trong nhánh thiết bị IoT với khả năng tính toán giới hạn. Lý do thì cũng dễ hiểu bởi các model 1 tầng này đòi hỏi tài nguyên khiêm tốn hơn so với 2 tầng. Sự khác biệt duy nhất với Two-stage detectors là bước học thứ 2 nhờ RPN bị loại bỏ, SSD thực hiện dự đoán khung hình cho regression ngay sau bước trích xuất đặc trưng trung gian. YOLO thì chia hình ảnh thành grid và xấp xỉ xác xuất tọa độ cũng như lĩnh vực nhờ các đặc trưng từ grid cho sẵn (prior). Nhờ vậy đúng như tên gọi, các anh em nhà YOLO chỉ nhìn vào toàn bộ hình ảnh đúng 1 lần. Do đó, tốc độ tính toán nhanh hơn FRCNN (nhìn vào từng phần ảnh nên lặp lại việc scan một số phần nhiều lần).
Tất nhiên, để lựa chọn một model phát hiện vật thể tốt cho business của riêng mình, thì đồ thị thể hiện tốc độ và độ chính xác có thể có ý nghĩa hơn. Các bạn có thể tham khảo đồ thị trên để tìm ra lựa chọn cho riêng bài toán của mình.
Thuật toán object detector là một phần của CVML và vì vậy ngoài phần ML thì phần xử lý ảnh là cần có. Lý do là bởi vì, camera đặt ngoài trời hoặc trong các tòa nhà các cơ sở thực hiện việc theo dõi thì có thể bị ảnh hưởng bởi yếu tố thời tiết, điều kiện ánh sáng mà thay đổi góc độ và tư thế của camera gọi chung là extrinsic factors. Ngoài ra, mỗi dòng camera lại có những ma trận thông số riêng, mà người ta gọi là intrinsic factors. Ảnh hưởng của hai ma trận thông số này tới hiệu suất của model trí tuệ nhân tạo là rất lớn. Ví dụ như hình ảnh ở bên, do thông số nội bộ của camera (intrisic) mà hình ảnh bị cong ở góc và viền, điều này rất có hại vì mội loại camera sẽ có một độ cong khác nhau, vì vậy việc cân chỉnh lại làm phẳng hình ảnh ra giúp tất cả các input được khôi phục ở mức giống nhau. Còn như hình bên dưới, cùng 1 khu vực hình vuông đã chọn, mỗi góc độ camera khác nhau sẽ cho ra 1 quan sát khác nhau. Quá trình cân chỉnh lại extrinsics giúp tất cả các input ở mọi góc độ được xử lý như nhau.
Sau khi cân chỉnh hình ảnh đầu vào đến chất lượng mong muốn và có được lựa chọn cho model object detection, việc tiếp theo là công nghiệp lắp ráp chúng lại thành hệ thống SDM mong muốn. Trong ứng dụng hiện tại, chúng ta không dùng intrisic calibration vì giả thiết là một loại camera duy nhất dùng để quan sát 1 cảnh duy nhất. Tuy nhiên, vị trí camera trong tòa nhà và góc quay cũng như tư thế quay có thể thay đổi. Vì vậy, extrinsic calibration cần được thực hiện. Còn về model object detection, chúng ta lựa chọn YOLOv4 do chất lượng cũng như ưu thế về tốc độ tính toán.

Đến đây, chúng ta cần hiểu tại sao ứng dụng SDM lại khả thi. Thứ nhất, chính là nhờ extrinsic calibration, làm đồng bộ hóa khoảng cách nên khoảng cách giữa hai điểm bất kỳ trên mặt phẳng ảnh và mặt phẳng máy là tương đồng. Cụ thể các bạn có thể xem lại giới thiệu về mô hình máy ảnh Pinhole. Thứ hai, chất lượng của mô hình phát hiện vật thể YOLOV4. Cần nhắc lại là cả hai mảng xử lý ảnh lẫn phát hiện vật thể đều quan trọng vì nếu không cân chỉnh góc độ camera thì hàm khoảng cách sẽ không cố định mà thay đổi theo góc độ camera (có thể do một luồng gió nhẹ hoặc động đất), hoặc hai vật ở xa sẽ nhìn thấy khoảng cách của họ nhỏ hơn khi họ đi bộ lại gần máy quay (mà vẫn giữ khoảng cách).
environment.yml với nội dung như sau:name: social-distancing
dependencies:
- python=3.8.5
- pip:
- opencv-contrib-python
- torch
- torchvision
- matplotlib
- ipython[all]
- jedi==0.17.2
- jupyterlab
conda env create -f environment.ymlgit clone --recursive https://github.com/JohnBetaCode/Social-Distancing-Analyser.gitcd Social-Distancing-Analyser && git clone --recursive https://github.com/AlexeyAB/darknet.gitDarknet: cd darknet && make -j8 && ln -s pwd/libdarknet.so .. && cd ..Một công cụ hữu ích gói phần mềm nói trên chung cấp cho chúng ta là ước lượng extrinsics factors. Như hình bên dưới, chúng ta sử dụng chương trình calibration/calibrate_extrinsic.py để thực hiện việc lựa chọn khu vực quan sát.
$ python calibration/calibrate_extrinsic.py -v Simwalk.mp4

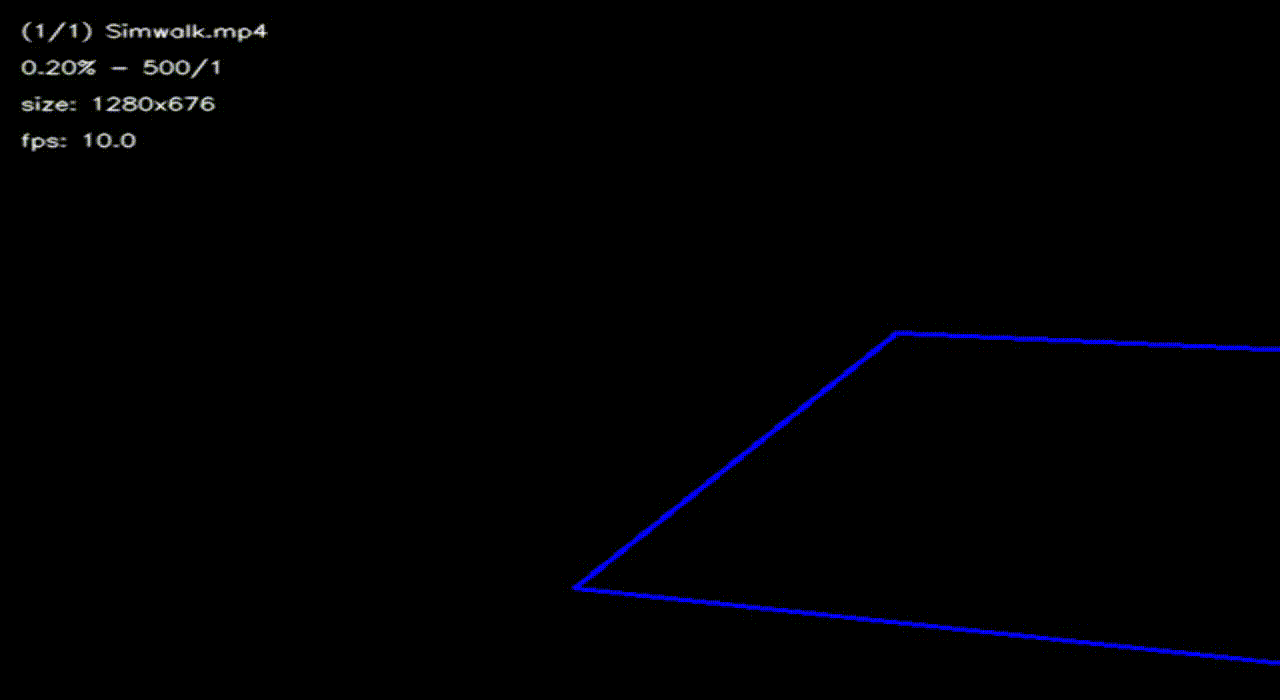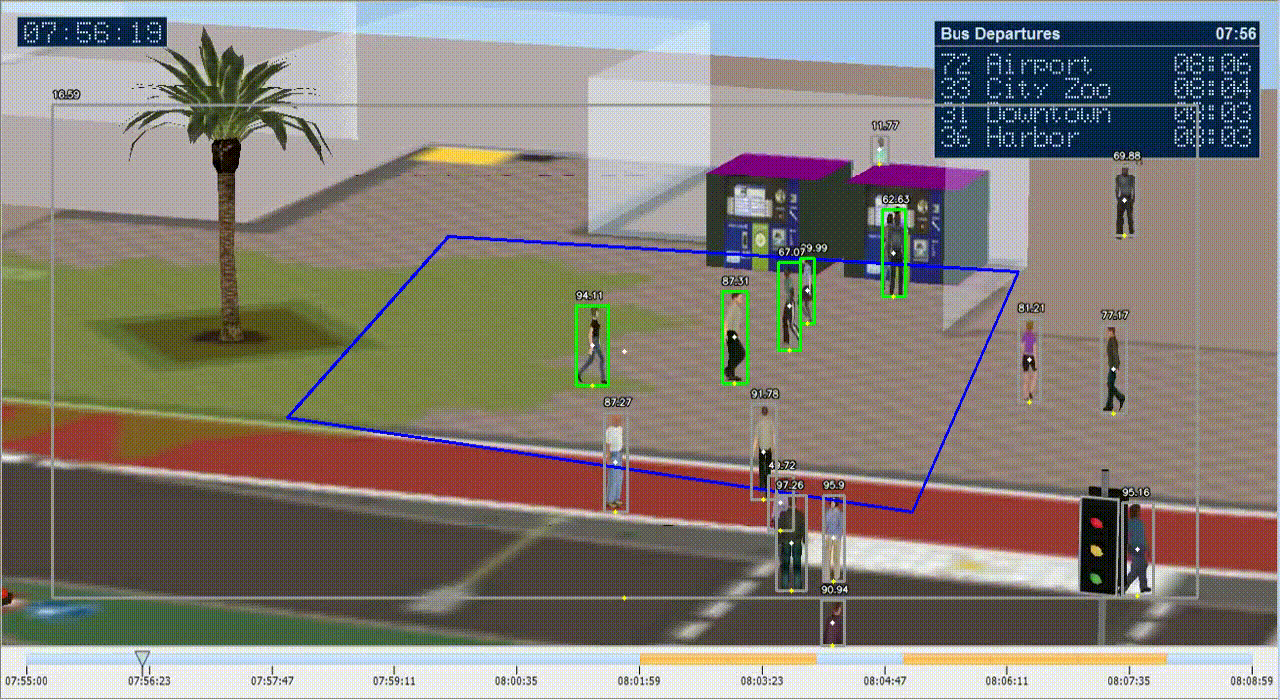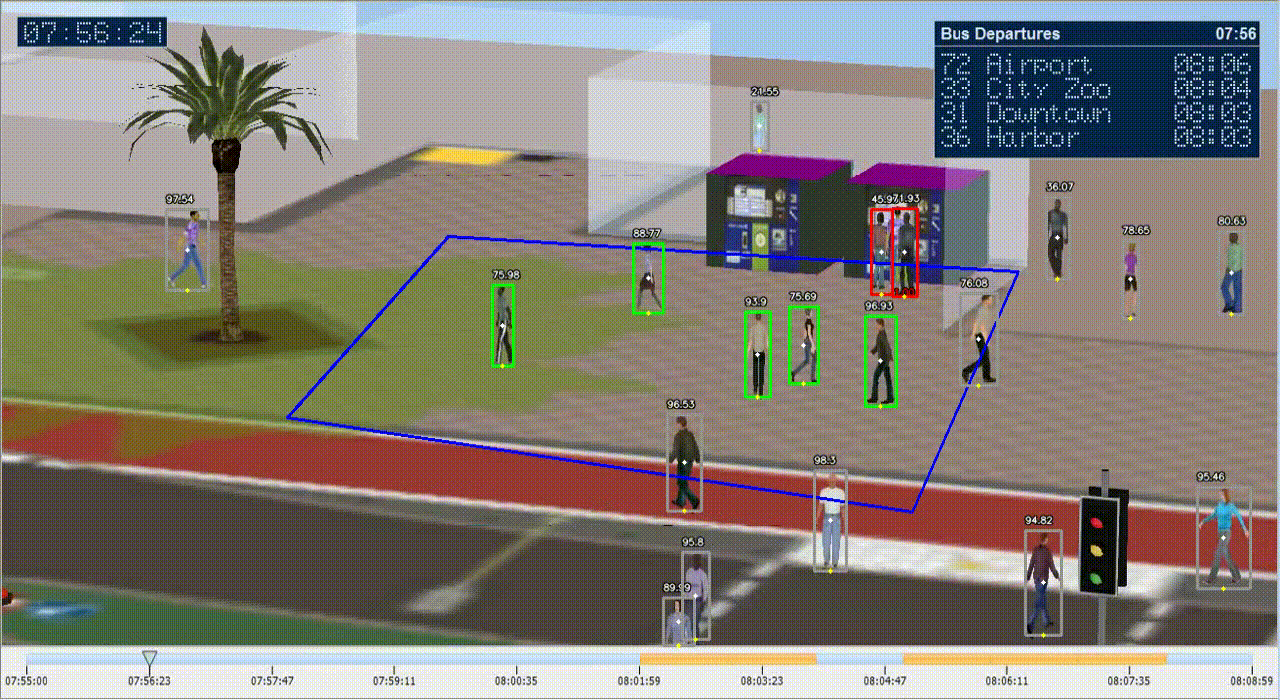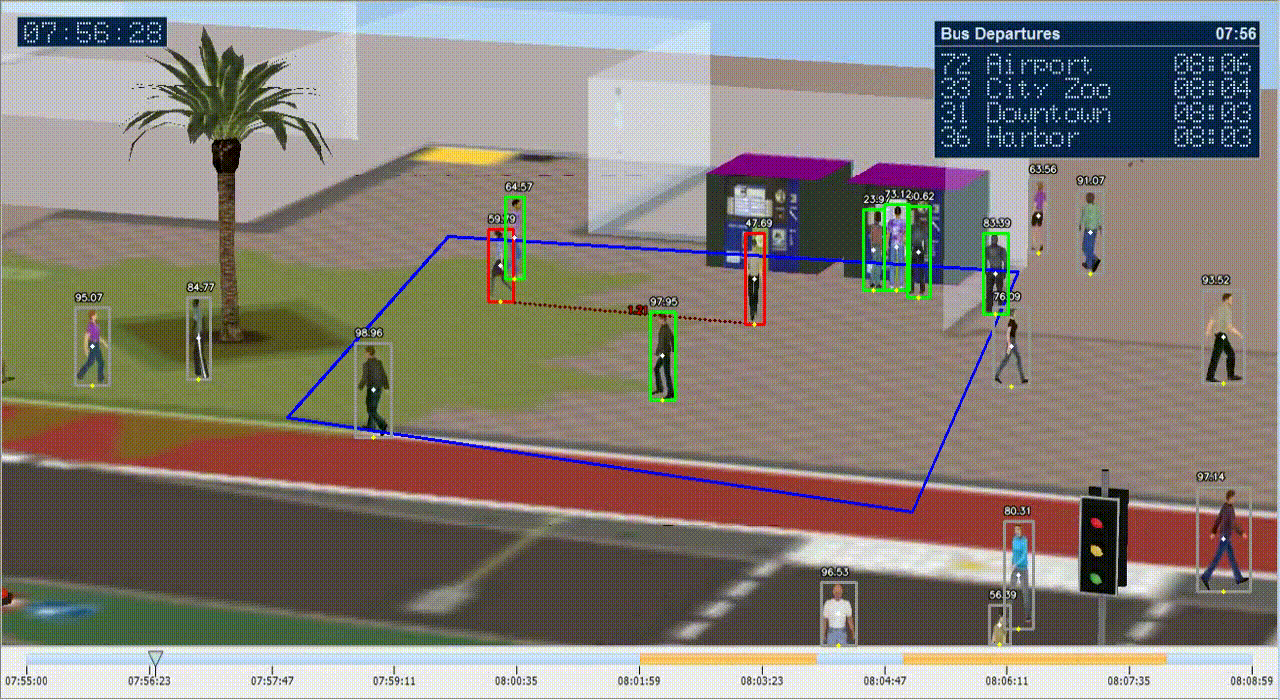
Ở trên đây, vì lý do bảo vệ riêng tư của người dùng, chúng tôi chọn giả lập cảnh bến chờ xe bus trên đồ họa vi tính. Khá nhiều dự án AI/IoT hiện tại khi làm với khách hàng nước ngoài đòi hỏi cao về riêng tư cá nhân nên sử dụng dữ liệu quay người thật để training và demo là không thể. Với lý do đó chúng tôi chọn dữ liệu giả lập (synthetic data). Để giả lập một bến xe bus có người qua lại các bạn có thể tham khảo phần mềm SimWalk. Sau khi tạo ra dữ liệu riêng, các bạn để file giả lập video vào thư mục media/. Trong quá trình thực hiện, ở cửa sổ bird_view các bạn sẽ thấy hình ảnh khu vực đã lựa chọn nhưng được warp lại để đảm bảo loại bỏ hết các yếu tố góc quay và di chuyển tịnh tiến vị trí quay. Nếu click chuột vào 2 điểm bất kỳ trong bird_view và nối chúng lại, các bạn sẽ được yêu cầu nhập khoảng thực tế của hai điểm đó theo mét. Nhờ nhập liệu này, chương trình ước lượng khoảng cách tương ứng mét so với 1 pixel ảnh. Thông số ước lượng được sẽ được lưu vào file configss/extrinsics.yml. Các bạn nhớ đưa ra ước lượng cả hai chiều x và y để đảm bảo độ chính xác.
Chúng ta sử dụng model YOLOv4 để phát hiện vật thể người trong ảnh. Đo khoảng cách được thực hiện theo việc đo số pixel giữa tâm của hai vùng vật thể. Khoảng cách được đổi ngược lại thành mét nhờ nhập liệu trong bước calibration trước. Khi người dùng có ước lượng bao nhiêu mét thì lên cảnh báo, chúng ta có thể set các thông số trong file cấu hình configs/env.sh:
# Social distancing analyser export SAFE_DISTANCING_TRESHOLD=2.0 # [float][meters] safe distance
Như cấu hình trên thì cứ hai người gần nhau dưới 2m thì khu vực xung quanh hai người đó được tô đỏ là hình thức cảnh báo. Video cảnh báo và các vùng radar như video dưới nhưng chúng tôi chỉnh cấu hình thành 0.5m.



Như vậy, nhở sử dụng công nghệ xử lý ảnh (Computer Vision), cụ thể là Object Detection, chúng ta đã xây dựng thành công một hệ thống Social Distancing Management. Do giới hạn về riêng tư người dùng, chúng tôi đã trình diễn trên dữ liệu video giả lập cảnh người qua lại tại bến xe bus nhờ phần mềm đồ họa SimWalk.
Rất cám ơn các bạn đã theo dõi bài viết.
You need to login in order to like this post: click here
YOU MIGHT ALSO LIKE

SUBSCRIBE TO OUR NEWSLETTER

